针对搜索引擎的各种开源技术是开源社区的一枝奇葩,它大大缩短了构建搜索应用的周期,并使得根据特定需求打造个性化应用的垂直搜索引擎系统成为可 能。作为一个独立的企业搜索应用解决方案,Solr在美国的众多知名网站中得到应用,如美国最大的科技资讯类网站CNet。Solr基于高性能的 Lucene开发,它不仅实现了比Lucene更为丰富的查询语言和更为优异的查询性能,而且实现了可配置、可扩展,对外提供类似于Web 服务的API接口。用户可通过Http请求向搜索引擎服务器提交指定格式的XML文件生成索引,也可以通过“Http Get”操作提出查询请求,并得到XML格式的返回结果。Solr结合其他开源搜索软件成为构建行业垂直搜索引擎的优选方案。
垂直搜索引擎的
总体结构
本文所述的电子元器件垂直搜索引擎以Solr 1.4为核心框架,综合应用Nutch、IK Analyzer等开源软件,充分利用它们灵活的配置、丰富的功能以及高效的性能,力求用最简单的代码,快速实现海量电子元器件信息的采集、文本搜索、参 数检索,满足技术研究人员与市场采购人员对于行业领域知识的专、精、深要求。
电子元器件垂直搜索引擎系统包括数据采集、数据加工、数据规划和管理、搜索服务四个主要部分。数据采集部分负责对Internet、 Intranet、内部电子文档、结构化数据(关系数据库、XML)等进行抓取、滤重、分类、摘要; 数据加工部分负责对采集来的数据进行筛选、编辑和审校; 数据规划和管理部分负责系统元数据的定义与管理,包括分类体系、特性参数、参数类型、计量单位等; 搜索服务则为用户提供分类导航、数据检索、行业报告及其他个性定制服务(系统的总体结构如附图所示)。本文结合选取其中的数据采集(Web页面抓取、结构 化数据采集、中文支持)、搜索结果呈现(层面浏览、高亮显示、分页处理)等几个重点实现方法进行介绍。
数据采集
1. Web页面抓取
采集互联网Web页面的数据并非Solr所长,我们可以借助在这方面有着突出表现的Nutch。Nutch基于Hadoop分布式系统,既可以在单 台机器上运行,也可以在多台机器构成的集群上运行。Nutch可以根据用户需要配置优先抓取某些页面,而且抓取质量很高。
本系统我们利用Solr作为处理搜索结果的源和入口,而让Nutch负责它最擅长的工作: 抓取和提取内容。Nutch的配置文件是nutch-site.xml,配置的内容包括指定蜘蛛的名称、激活插件、限制单机一次运行抓取的最大URL数、 指定抓取规则等。完成这些基本配置以后就可以进行抓取分析操作。
2. 结构化数据采集
为了充分利用现有资源,提高数据检索效率,我们把收录了100多万条电子元器件产品、1000多万条特性参数信息的中国电子元器件产品数据库和中国 电子厂商数据库、韩国电子元器件信息库作为结构化数据源,向Solr一次全部导入数据,后续维护的部分使用增量导入。用于搜索的表主要涉及产品基本信息 表、厂商基本信息表、分类表、特性参数表、参数模板表、模板信息表、产品特性参数值表、计量单位表等。
Solr通过可配置的方式将数据库中多列、多表的数据生成Solr文档。配置的方法是在域结点内定义具体的字段(类似数据库中的字段),然后通过配 置文件导入所有数据,发现并处理由插入、更新带来的变化。
3. 中文搜索支持
Solr的分析包并没有直接提供中文搜索支持。这里选用轻量级的中文分词工具包IK Analyzer来配合工作。IK Analyzer基于Java开源,如今新版本的IKAnalyzer 3.2.0已发展为面向Java 的公用分词组件,独立于Lucene 项目,同时提供了对Solr的专用接口。
电子元器件搜索引擎系统利用的IK Analyzer特性包括: 特有的“正向迭代最细粒度切分算法”具有60 万字/秒的高速处理能力; 多词元处理器分析模式,支持英文字母(IP 地址、Email、URL)、数字(日期、常用中文数量词、罗马数字、科学计数法),中文词汇(姓名、地名处理)等分词处理; 优化的词典存储更小占内存用; 针对Lucene 全文检索优化的查询分析器IKQueryParser; 采用歧义分析算法优化查询关键字的搜索排列组合,可极大地提高检索的命中率。
由于电子元器件垂直搜索应用面向特定的专业领域,IK Analyzer本身虽然已经提供很丰富的常用词汇,但对于专业性强的应用仍然显得捉衿见肘。好在IK Analyzer提供了良好的扩展能力,我们利用配置文件轻易实现了用户词典的扩展与定制,这样就可以搜索到如“精密薄膜柱状无引线电阻器”、“半波随机 型固体继电器”这些专业词汇了。
搜索结果呈现
Solr的搜索结果通常以XML格式返回,这对于普通用户而言不合适,不过Solr提供了多种途径(如正则表达式和文本解析)将搜索返回的结果信息 进行重新布局,以产生用户易于理解的可视页面,但都需要大量的编码工作。在系统中我们利用XSLT把XML格式的结果文件转换成HTML文件。经过转换 后,就可以得到能看到搜索结果的页面了。
Solr提供了层面浏览(facet)功能,它类似于一种分类筛选。运行层面无需在Solr 中进行配置,但可能需要按照新的方式对应用程序内容进行索引。在已索引的字段中完成分层,层面对未进行断词的非小写词最为有效。Facet 字段通常不需要存储,因为分层面的总体思想就是将可读的值显示给用户。要注意的是, Solr 没有在层面中创建类别,必须由应用程序自身在索引期间进行添加,正如在索引应用程序时给文档指派关键字一样。如果存在层面字段,Solr 就提供了查明这些层面及其计数的逻辑。
另外,为了在搜索结果中取得最匹配的一段文本并突出显示出来,有必要对搜索结果进行高亮显示。高亮显示可修改配置文件实现。该配置中包括了高亮文本 时使用的前缀和后缀(通常在此指定突出显示文本的字体、字号、颜色或其他风格)。
如果搜索结果较多还需要分页,但我们不希望自行编写复杂的代码实现分页。我们在系统中使用了一个开源的分页插件,专门为Solr量身定制,由它对 Solr 的搜索结果进行分页处理。
实际上,Solr的功能远不止以上这些,还有很多通过简单配置和少量修改即可实现的搜索功能有待研究开发。目前,我们围绕以Solr为主体的探索以 及各项功能的实现仍在继续,力求在保证系统功能与性能的前提下,充分利用开源软件的优势,降低开发成本。
(作者单位:董娅为电子工业出版社、周峻松为工业和信息化部电子科学技术情报研究所)
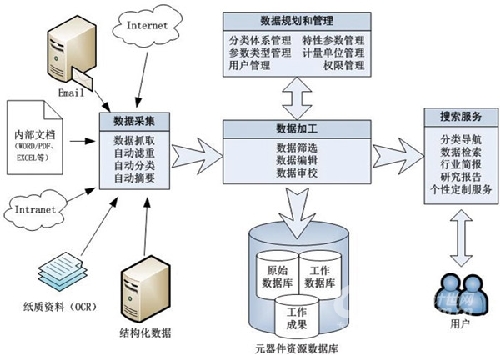 |
图注:电子元器件垂直搜索引擎系统结构图



0 条评论。